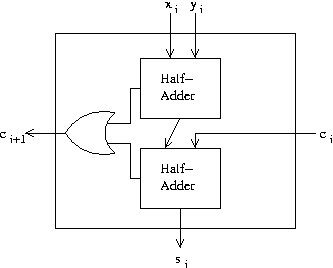
Recall how we make a full adder out of two half-adders:
For the 2i digit, we add bits xi and yi yielding si; carry in is ci and carry out is ci+1.
usually c0 = 0 (i.e. the carry in to the least-significant-bit adder)
and the least significant bit's addition is called number 0, the most significant bit is called number n-1, so cn is the carry out from the entire addition.
For a half adder we had c = xy and z = x xor y.
For the full adder, we're adding xi and yi, then adding that to the carry in. So the sum turns out to be si = xi xor yi xor ci (where ci is the carry in, and ci+1 will be the carry out)
(xor is associative, although it seems strange; so no order of operations issues; xor is also commutative)
Then as for the carry out, we realized that although it seems we should be adding together the carries from the both of the half-adders, it was impossible for both of them to carry, so we could just OR together these two half-adder carries.
So, since xiyi is the carry out from the xi+yi half-adder, and it's ORed with the carry out from the bottom half-adder, we get:
ci+1 = xiyi + (xi xor
yi)ci
= xiyi + xi yibar
ci + xibar yi ci
-- xor definition, and distributive law
= xiyi + xi ci +
yi ci
-- see next paragraph.
I didn't do the proof of the equivalence of the last two lines in lecture but it makes a good exercise, or I've written it out on a separate web page. But the result is reasonable, it says that we carry if and only if any two of the three are 1. (This includes the case where all three are 1.)
We can call our basic multi-bit full adder diagram a "ripple adder", because it has the same propagation delay issues as with a ripple counter. There exist ways to decrease the excessive propagation delay for a big adder -- 32 bit cpu bus widths are reasonably common these days, so they'd have to be slow if they used ripple adders -- but these techniques are somewhat nasty. The basic idea behind the "synchronous adder" is the same as with the synchronous (non-ripple) counter, except what we call the "propagation function", what you could call a "predictor" as to whether or not the previous flip-flop would carry, is more complicated. For a counter, it's just the AND of all the previous bits. But for a multi-bit adder, it's a more complex formula which I don't think it's worth introducing in this course (although there is some discussion in the textbook). The important points here are that: (1) we have a ripple problem, and: (2) a solution exists. But unlike the ripple counter, the ripple adder solution uses a number of additional gates which is not linear in the number of bits.
(When we discuss machine-language programming, cn will be used for the C condition code.)
If we ignore the carry aspect and treat the numbers as unsigned, we get arithmetic modulo 2n.
Modular arithmetic is like arithmetic with "wrap-around" -- when we get to 2n (e.g. 65536, if n=16), that's zero again. So for example we write that 65536 === 0 (modulo 65536).
Throwing out the carry bits is like taking only the low however-many bits (32 bits in the case of a 32-bit CPU or 16 bits in the case of the PDP-11). This is how our counters have all worked so far: if we have a three-bit counter it counts to 7 and then after 7 comes 0.
Consider a four-bit number:
if we start with three (0011) and subtract one, we get two (0010)
keep subtracting...
0001
0000
now if we have a four-bit counter, that 0000 would follow 1111, and
continuing back in time we see 1110, then 1101, ...
let's call these negative.
So we have
0001 we call "1"
0000 we call "0"
1111 we call "-1"
1110 we call "-2"
1101 we call "-3"
This is called the "two's-complement" representation.
Now, eventually we'll get back down to zero... where do we draw the line between negative and positive numbers?
Well, we want about half each, so to keep things simple we designate the left bit as the "sign bit", to be read somewhat like a minus sign: it indicates whether the number is negative.
So: we may or may not be using this "two's-complement" scheme. There are two interpretations of an n bit integer:
unsigned interpretation:
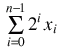
Possible values: 0 through 2n-1.
signed interpretation:
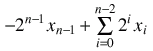
Possible values: -2n-1 through 2n-1-1.
Note that signedinterpretation = unsignedinterpretation -
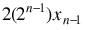
= unsignedinterpretation -
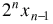
thus the signed interpretation is congruent to the unsigned interpretation, modulo 2n, which just means that they differ by a multiple of 2n. Such as zero, or 2n (or -2n).
Algorithm: To compute the two's complement (i.e. to negate a number
arithmetically), take the one's complement and add one.
To compute the one's complement, invert all of the bits.
Note how different the algorithm is from the definition of the meaning of two's complement...
One use of two's complement is to subtract. It's easy to compute the two's complement of a number; to subtract, add the two's-complement, ignoring the carry-out!
For example, in 8 bits:
12 is 00001100
the one's complement is 11110011
so the two's complement is 11110100
(n.b. the number of bits affects the one's complement! and hence the two's complement)
29 00011101
-12 + 11110100
---- --------
00010001
(I suggest copying that out and doing the binary addition
right-to-left, showing the carries)
Now, in converting this to decimal, no need to include all those "0*" terms
= 1*24 + 1*20
= 17
Note that 11110100 can be considered to be either 244 or -12. In the two's complement representation (signed interpretation), we take it to be -12, because of the "sign bit".
The sign bit rule gives us numbers in the range -27 (-128) to 27-1 (127).
1=negative, 0=positive or zero.
So what does this two's-complement algorithm yield, really?
Take a number:
xn-1 xn-2 xn-3 ... x0
(arbitrary binary digits xi)
one's complement: write the above with overbars
two's complement: can't see how to write it like this.
So compute it (in general):
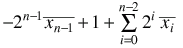
do the complementing -- [note that a formula for qbar is 1-q -- try it out, only two possibilities, both work]
=
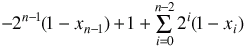
multiply them out
=
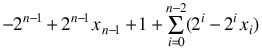
[ Since
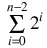 =
=
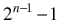 , ]
, ]
=
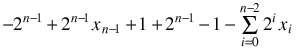
We're adding and subtracting both a 2n-1 and a 1, so:
=
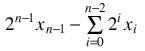
=
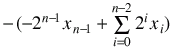
which bears a notable similarity to the interpretation of our original number.
Imprecise conclusion: The two's complement of x is -x.
In fact it works except for -2n-1, the most negative integer, minint.
It can't work for -2n-1! Because the maximum int is -2n-1-1; minint's arithmetic negation is unrepresentable!
What do you get if you apply the two's complement algorithm to -2n-1?
well, -2n-1 is going to look like 100000.....
one's complement yields 0111111.....
add one, will carry and carry to 100...00, i.e. all
zeroes except with the sign bit 1.
This is -2n-1! So -2n-1 is its own two's complement! It overflowed in that addition of 1.
-2n-1 is anomalous. Two's-complement is an arithmetic negation for everything else. In general, taking the two's-complement of -2n-1 yields a value which is congruent to the correct value mod 2n-1.
The placement of the +1 is what makes the above proof imprecise.
Correct conclusion: The two's complement of x yields the same thing as adding 1
to (-x-1).
This is -x,
unless x is -2n-1, in which case the one's-complement is the
maximum integer, and adding one to that overflows.
So now, when we add numbers, some of them can be negative. If we add numbers together including some negative numbers, or all negative numbers, it's an easy theorem in modular arithmetic that we will still get some value congruent to the correct answer, modulo 2n.
But is it the correct answer?
The response to this question is to compute the "overflow" bit -- it's analogous to bits falling off the left side, but it's not actually the same as the carry-out:
The carry-out is like the overflow for the unsigned representation. What we are seeking now is how to compute the overflow information for the signed representation.
example: in 16 bits (216 = 65536):
If the correct answer is 65534,
we will get 1111111111111110, which we call "-2", so it's the wrong answer.
If we get the wrong answer (albeit something which is congruent to the right answer, modulo 2n), we set the overflow bit. Otherwise, we clear it.
Computing the overflow bit for addition:
We have overflow iff the sum is not representable. For example, in four bits,
we can represent from -8 to 7. If we take 5+5, that's 10, which is not in
range. If the result is in range, the full adder scheme will work, for
positive or negative numbers.
For non-negative numbers, overflow is simply the carry in to the msb.
More analytically,
Let minint = -2n-1
[Draw: number line going from (and beyond) minint*2 to -minint*2, with markings minint*2, minint, 0, -minint, -minint*2. Brace on top indicates "representable numbers" (from minint up to but not including -minint). Arrows indicate that leftmost group "appear positive" and rightmost group "appear negative".]
For two non-negative numbers,
If 0<=x<-minint and 0<=y<-minint, then 0<=x+y<-minint*2.
If x+y<-minint, we have no overflow.
If -minint<=x+y<-minint*2, x+y will appear to be negative (overflow).
Thus I) The sum of two non-negative numbers overflows iff the sum appears negative.
That's exactly when the sum is not representable in n bits. (We can't use the leftmost bit to represent the number, that's the sign bit.)
For two negative operands, overflow isn't simply cn-1. But what it has in
common with the two-non-negative case is that we get overflow exactly when the
result appears to have the wrong sign.
If minint<=x<0 and minint<=y<0, then minint*2<=x+y<0.
If minint<=x+y, we have no overflow.
If x+y<minint, x+y will appear to be non-negative (overflow). because of the
mod 2n wraparound property. As opposed to the previous case, where
minint<=x+y, in which since we have no overflow and since we know that x+y<0,
x+y will appear to be negative (and should be negative).
Thus II) The sum of two negative numbers overflows iff the sum appears non-negative.
If the two operands have opposite sign bit (msb vs not(msb), i.e. sign BIT, i.e. 0 is in with the positives), it's not possible to overflow. Proof:
If minint<=x<0 and 0<=y<-minint, then
minint+0<=x+y<0+-minint
minint<=x+y<-minint
so the sum is in the representable range. so (III) the sum of two numbers of
opposite sign bit cannot overflow.
So, combining all three cases:
Thus addition overflows exactly when the sum (s) of two numbers (x+y) of
matching sign appears to have the opposite sign.
So,
overflow (true/false) =
xn-1yn-1sn-1bar
+
xn-1bar yn-1bar sn-1
(that's the "or" plus sign, and the "and" multiplication notation)
Can we come up with a simpler formula for overflow? Not in terms of x, y, and s. But we have other information available to us, other values lying around which have already been computed. It so happens that overflow = cn xor cn-1!!
The proof in boolean algebra is tricky, mostly because it's long. But it exists. You can prove equivalence from the "s" and "c" formulas we started with.
In a multiword addition, ignore overflow bit except for in the final addition. In effect, the words other than the most-significant word are unsigned.
subtraction:
To subtract, add the two's complement.
Just as we used the carry-in to the ALU to help us add one to the PC in our
microcode,
we can use the carry-in to the ALU to do the adding of 1 to form the two's
complement.
Furthermore, adding the one at the same time as we do the overall addition will
improve the meaning of the overflow flag.
So more simply, what we need to do is:
Invert bits of subtrahend and set carry-in.
The "subtract" control line will invert the bits of the subtrahend and do an "add"; it's probably up to the microcode to set the carry in, for a reason we'll see shortly -- there is a situation in which you do not want to set the carry in.
(example subtraction above)
Multiplication of non-negative numbers (n.b. non-negative!):
"schoolchild method" -- the way most of us do multiplication by hand, where you
multiply the first operand individually by each digit of the second operand,
and you write them shifted over in the appropriate way so that when you add all
the sub-products, you get the product.
There are lots of tricks you can use to do multiplication, though.
I used to be pretty good at doing arithmetic in my head, using tricks.
Consider this multiplication: 63*35
I used to be able to do that easily in my head, to get = 2205.
How do I do that?
Well, I notice that 63 is a multiple of 3, and I know off-hand what 35*3 is,
it's 105.
I know a large number of fairly assorted facts like this, e.g. that 35*3=105.
So 63*35 = 105*something... what's the something? Well actually I know that 63
is 9*7, that's part of the times tables I memorized in grade four, and so I
want (9*7)/3, which is (9/3)*7, or 3*7, which is 21, so = 105*21. That's an
easier multiplication to do directly in your head than 35*63, probably -- 1*21
is simply 21, and 5*21 is 105, for a total of = 2205.
So, I have a bag of tricks like this in my head, but it's a pretty assorted bag. But when we get to computer arithmetic and we're working with binary numbers, since there are only two possible digits, there are more likely to be nifty tricks; a given nifty trick is more likely to apply, so we can get more out of a small number of them.
But first, let's do the schoolchild method with some binary numbers.
In decimal:
63 *35 ------ 315 189 ----- 2205In binary:
111111
*100011
-------------
111111
111111
000000
000000
000000
111111
-------------
100010011101
(I suggest writing this on paper and showing the carry, as I did in lecture.)
Now, first of all, note that the multiplication is trivial. It's really just an "and". But more than that, if it's a 1, you just copy down the whole first operand; if it's a zero you can omit that row.
Another way to say this is that we are discarding zeroes. That is,
35 = 25 + 21 + 20 -- discard zeroes
We've discarded zeroes... what's left... let's discard ones!
Any run of ones can be collapsed into two terms.
Collapsing runs of ones:
Let's consider a number with a bigger run of ones: 1001111000
1001111000
= 1*29 + 1*26 + 1*25 + 1*24 + 1*23
= 1*29 + 1*27 - 1*23
In general:
Requires a maximal run of ones; that is, the digit to the left of the
run of ones has to be a zero.
0111...1 + 1 -------- 1000...0
So, if 0111...1 + 1 = 1000...0,
then 0111...1 = 1000...0 - 1.
This leads to Booth's algorithm (HVZ 5e 6.4.1, or Stallings ), which is based on this collapsing. I don't think we need to get into the details of Booth's algorithm, just the basic idea of collapsing runs of ones.
Note that the schoolchild algorithm only works with unsigned operands. Booth's algorithm also takes care of the two's complement representation. Not too hard... look at the spaces in the 63*35 addition -- those are basically zeroes -- some of those have to be ones, in a sign-extension kind of way.
There exist faster multiplication algorithms. Some notes in HVZ.
Floating point representation
What about non-integers?
Some CPUs have floating-point arithmetic instructions; a growing number. With graphics demands (e.g. simply from windowing systems), floating-point instructions are pretty much required these days.
e.g. suppose we want the number two and a half?
First, an example of a simple representation for non-integer numbers.
It involves adding something like decimal points, but "decimal" means base
10...
so we tend to call it a "binary point", or there's a generic term "radix
point", "radix" basically meaning "base".
I claim that we can represent 2½ by 10.1 in binary.
10.12
= 1*21 + 0*20 + 1*2-1
= 1*2 + 0*1 + 1*½
= 2 + 0 + ½
= 2½
With a specified position designated as the 20 bit, this scheme is called "fixed point" (you've heard of floating point, next)
How many bits do we need to be able to represent Avogadro's number? (6.02x1023)
602000000000000000000000 < 279 (slightly less than)
thus it could be represented in 80 bits in sign-and-magnitude format (or
two's-complement) (not 79 bits: one bit for the sign bit)
But in fact there is not close to 80 bits' worth of data there! Big waste. Also takes more CPU power/time to process.
Alternative: use something very much like the scientific notation.
But based on base two, of course.
6.02x1023 is approximately (1 and 63/64)x278
or 1.111111 (base two) x 21001110 (base two)
So we'll use a data format with different "bit fields" for these two numbers (1111111 and 1001110).
The commonest floating-point format is the one defined by the IEEE floating-point standard (IEEE 754):
If the "exponent" field contains the signal value of 11111111, the "mantissa" field indicates a "special value" which is either:
A fuller description of the IEEE 754 format, including an example detailed conversion to and from IEEE 754 format, can be found in representation.html in my old CSC 270 notes.
How to implement floating-point addition in circuitry?